Understanding HTCondor Logs
By: Immanuel Bareket, UCSB
In collaboration with Igor Sfiligoi, UCSD/SDSC
Summary
The ShadowLog provides a detailed description of a job as it moves through the condor system from when it is submitted until it terminates. For a typical job, the logs are relatively concise and understandable. However, the logs for a job that isn’t processed regularly are long, and difficult to understand. There is no consistent way to differentiate between user errors, system errors, and irregular log messages that are not errors at all. There is also no documentation on the expected state transitions for a typical job, and what that should look like in the logs. All of these are necessary to better recognize error patterns and make progress in error characterization.
We thus propose that documentation is added to the HTCondor website outlining the typical states a job should go through, and the corresponding log messages.
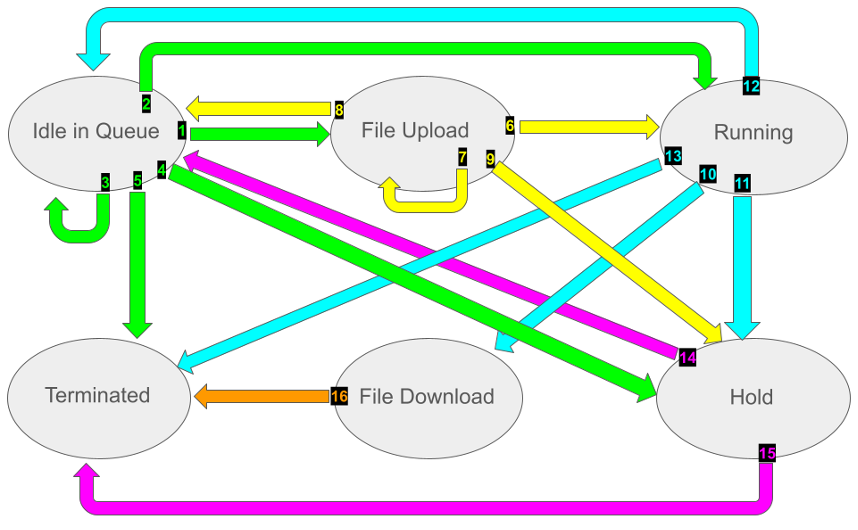
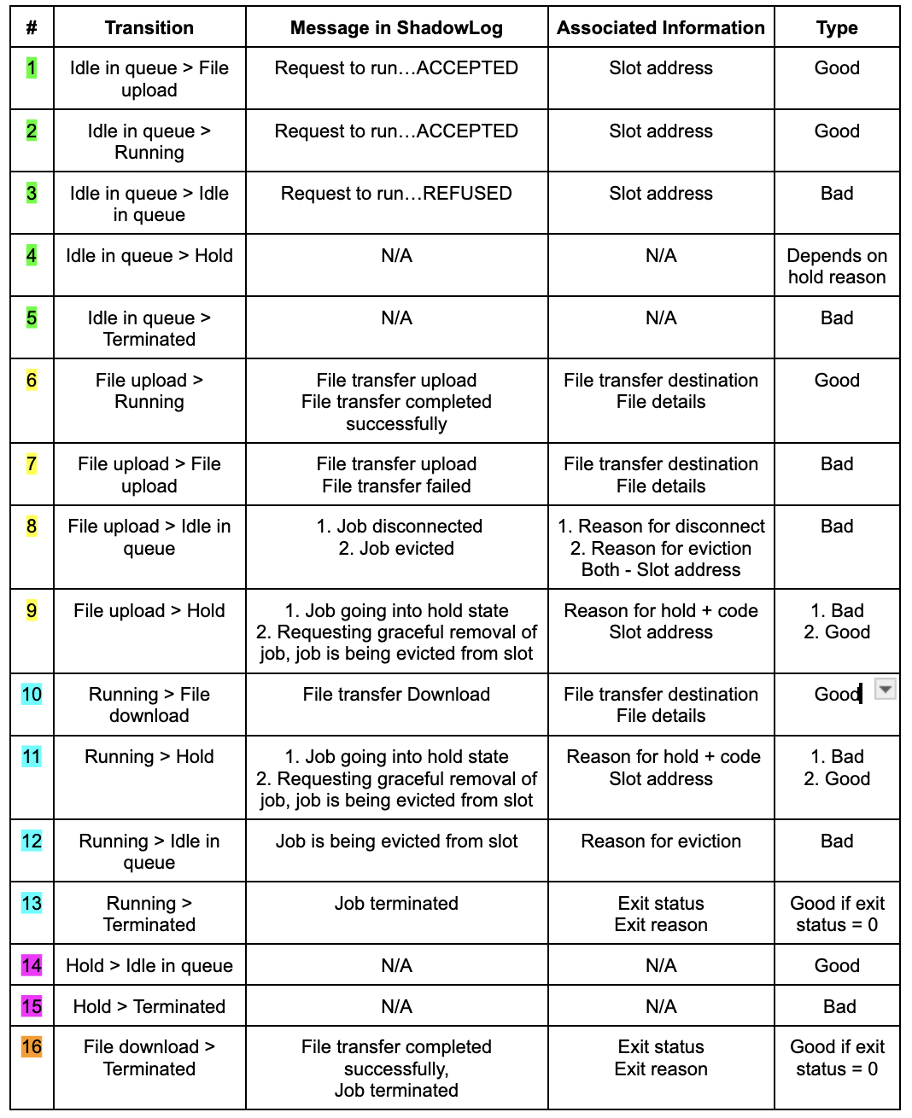
Condor State Transitions
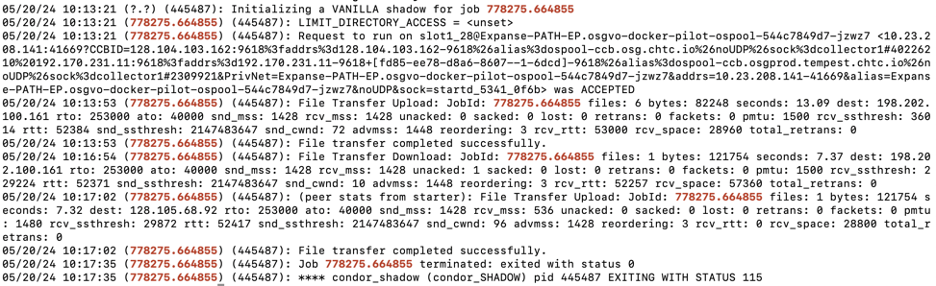
Example ShadowLog for regular job:
Example ShadowLog for bad job:
(Note that logs for bad jobs can vary greatly depending on error)

Additional observations
- Fatal vs Non-fatal errors
- A “bad” job can experience a fatal error and terminate with a non-zero exit status or it can recover and terminate with exit status 0.
- Common non-fatal errors include but are not limited to: refused requests to run on a slot, file transfer failures, holds.
- A “bad” job can experience a fatal error and terminate with a non-zero exit status or it can recover and terminate with exit status 0.
- User vs System errors
- Hold codes, reasons for eviction/disconnect, and other descriptive features can make it easy to determine whether an error is the fault of the user or the system.
- In errors that lack descriptions, it can be much more difficult. e.g. File transfer failures, unknown reasons for eviction/disconnect
Parsing ShadowLog manually
Parsing ShadowLog with python
https://github.com/emanbareket/HTCondor_Immanuel/tree/mainPossibilities for future advancement:
- Looking deeper into the “Associated information”:
- This information can be tracked at each transition and used to predict whether errors are user or system related.
- This predictive logic can then be used to improve condorErrorTracker.py, or any other future script, allowing it to filter out and focus only on system errors.
- Patterns in this information could also allow us to pinpoint specific causes of errors, and potentially be used to fix errors faster, or even prevent them.
- Predicting whether jobs will recover:
- As of now, it is very difficult to predict whether or not a job will recover from an error, as you usually only know the error is fatal when the job terminates, and there is seemingly always a chance for it to recover before then.
- We could track the percentage of jobs that recover after experiencing every type of error, and use this to directly calculate the recovery probability for each error.
- We could also simply keep track of errors that are always fatal, though they may be scarce or not even exist.
- Machine learning can be used to find less visible/obvious patterns and make even better predictions.