Data robustness and scalability on Open Science Grid
by Fabio Andrijauskas and Frank Wüerthwein - University of California San Diego, as of December 31, 2021
Objective
This document provides a set of results about the data access in the Open Science Grid (OSG). The objective is to show issues on data access of an OSG job. All the process follows a methodology to understand how a user requests the information and any problem with this process.
Executive summary
Robustness is the degree to which a system or component can function correctly in the presence of valid inputs, and scalability is the responsiveness of a service with a reasonable performance given as the use of the service increases. Underlying this activity is the notion that robustness may deteriorate as scale of use of the service increases. To measure such a possible deterioration requires a set of benchmarks and tests accessing the data using different methods to check all these measures for robustness as a function of scale.
We have origins and caches on the OSG data federation, and the origins have data from various experiments. Caches have a way to provide data “locally” and speed up the process for the jobs. With numerous jobs running, it is necessary to detect when a job fails due to data access. After more than 10,000 jobs using a methodology to explore several data access methods, the following issues in the OSG Data Federation infrastructure were found:
-
The Chicago XrootD cache was found to exhibit a performance issue during one of the tests. This was traced to a feature in the XRootD software that makes it possible (in principle) for a single slow response origin in the federation to bring down the performance of all caches of the federation. Details are given below.
-
We propose that the OSG software team, together with the OSG production team engage in a conversation on amelioration of this problem in one of the following ways:
- The XRootD team protect the software against this failure mode in some fashion.
- The OSG team develop a monitoring and deployment scheme to observe and protect against this failure mode.
-
-
The Kansas city XrootD cache is prone to overload issue due to the way GeoIP localization for the closest cache is implemented in the OSG Data Federation. Whenever GeoIP fails to find the location of a client’s IP address, it defaults to the geographic middle of the USA. The Kansas cache is the closest cache to that middle, and thus all cache accesses with failed GeoIP have to be served by that cache. This makes that cache prone to overloads, thus reducing the overall reliability of the OSG Data Federation.
- We propose a change in the logic for the “closest cache” location choice. Any time the location of the client is the middle of the USA, the OSG software should pick a cache at random from a list of known functional caches, rather than always the Kansas cache.
-
UCSD XrootD cache is slow compared with the other caches.
- We propose that a ticket is opened with the UCSD T2 to investigate this further. There was no obvious pattern here which may indicate a partial hardware failure on some disk, or NIC, or some such.
-
The system to check the closest cache needs an analysis; several sites use only the Kansas City Cache.
- We propose a systematic analysis is done to understand why these sites consistently fall back to the Kansas City Cache. We suspect that their worker nodes do not resolve their IP via GeoIP but investigating this further was deemed outside of scope here.
-
+DESIRED_Sites instruction is not followed sometimes by condor system.
- We propose a follow-up investigation. We are concerned that this could point to some deeper problem in HTCondor and/or the way it is configured and used in OSG. Such a follow-up investigation was deemed out of scope for this activity.
-
OSG login node is very slow sometimes.
- We propose OSG production to monitor the performance and load of the osg-connect access points to gain consistent awareness of load issues there.
Detailed description
Robustness is the degree to which a system or component can function correctly in the presence of valid inputs or stressful environmental conditions, and scalability is given a reasonable or good performance on a sample problem with a commensurate increase in computational resources [1,3]. One method to measure is one procedure referred to as FePIA [2,4], where the abbreviation stands for: identifying the performance features, the perturbation parameters, the impact of perturbation parameters on performance features, and the analysis to determine the robustness. For OSG it is required to check how a system could use computation resources related to robustness and scalability. There are many ways to execute code and access data on OSG data federation, and almost all interactions are through jobs.
We define a set of benchmarks and test accessing the data using different methods to check all these measures for robustness and scalability. We have origins and caches on the OSG data federation, and different origins have data from various organizations. XrootD caches can provide data “locally” and speed up the process for the jobs. However, numerous jobs running are required to detect when a job fails due to data access, and we do not have this monitoring. Figure 1 shows the basic idea of a job accessing data.
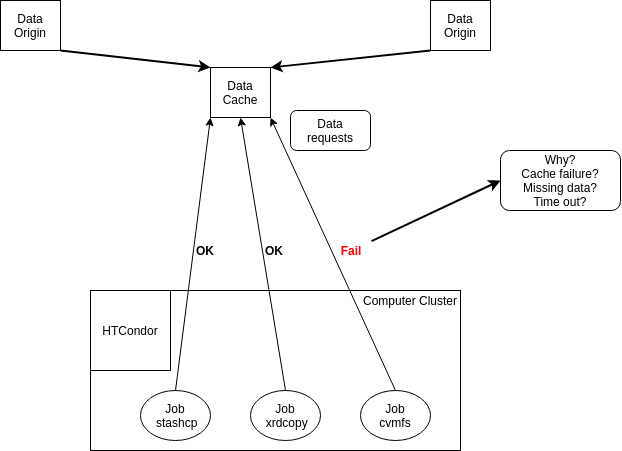
Methodology
To monitor data access requires analyzing three data access methods:
-
stashcp: Stashcp uses geo-located nearby caches to copy from the OSG Connect’s stash storage service to a job’s workspace on a cluster [5]. The stashcp, by default, try to use cvmfs, xrootd, and HTTP to access the files.
-
xrdcopy: copy directly from a location. It is possible to check the nearest cache using the stashcp command or using the GeoIP service directly.
-
cvmfs: copy directly from a file system. It is possible only to check where the closest cache.
As users of OSG may use any of these methods, we chose a testing methodology that tested all of them independently of each other. Thus, checking the robustness and scalability is based on request files using stashcp, xrdcopy, and cvmfs in a different order with different files size and other variables following Table 1. We implement two different ways of accessing data via cvmfs. First as a simple cp from cvmfs to the local worker node, second as a direct posix read from cvmfs. There are thus 4 access methods, three of them are full file cp and the fourth is a posix read.
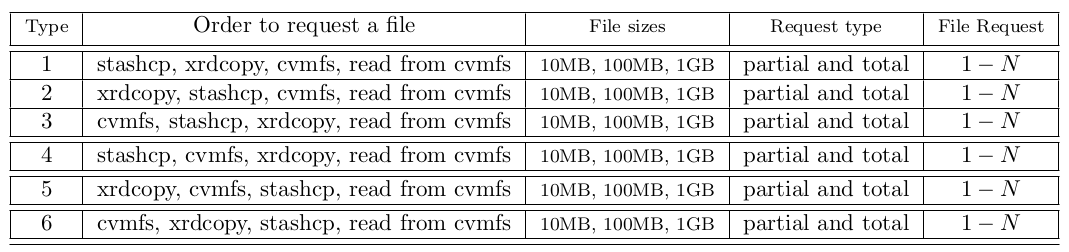
The following steps are to measure the failure statistics for each of these 6 job types:
- Create the files on the /osgconnect/public/ with random names;
- Request the files following Table 1 using a condor job on different sites;
- Collect data about the requests;
- Delete the files from /osgconnect/public/;
- Back to step 1;
Implicit in these steps is that each job accesses 4 randomly named files. And each file needs to be copied via the cache from the origin. We are thus testing the situation of an “empty cache”. We consider this a worst case scenario for robustness. A “full cache” is less likely to fail than an empty cache because in both cases the cache is exercised but only the empty cache exercises the cache connection to the origin.
Results and conclusions
All these tests showed some issues in the OSG environment related to data access. Figure 2 shows statistics about the executed tests.
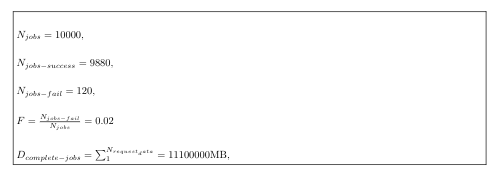
Table 2 shows some errors found during the execution of the jobs. Some network problems are shown on lines 1, 2, 4, 6, and 9 in Table 2. The errors on lines 3 and 5 could be related to the high load on the Chicago cache. Error number 7 was not part of the failure on statistics. However, it is a source of a problem in a user’s process.
Table 2: Errors found in the execution of the test.
| Date (Y/M/D) | Error Message | |
|---|---|---|
| 1 | 2021-11-10 | Unable to look up wlcg-wpad.fnal.gov |
| 2 | 2021-11-10 | Unable to resolve osg-kansas-city-stashcache.nrp.internet2.edu:1094: Name or service not known |
| 3 | 2021-11-01 | osg-chicago-stashcache.nrp.internet2.edu:1094 #0] elapsed = 0, pConnectionWindow = 120 seconds. |
| 4 | 2021-11-01 | [osg-kansas-city-stashcache.nrp.internet2.edu:1094 #0] Unable to resolve IP address for the host |
| 5 | 2021-11-15 | [osg-chicago-stashcache.nrp.internet2.edu:1094 #0.0] Unable to connect: Connection refused |
| 6 | 2021-10-26 | [osg-gftp2.pace.gatech.edu:1094 #0] Stream parameters: Network Stack: IPAuto, Connection Window: 30, ConnectionRetry: 2, Stream Error Widnow: 1800 |
| 7 | 2021-10-26 | Write: failed Disk quota exceeded (from my user account) |
| 8 | 2021-11-01 | ERROR Unable to look up wlcg-wpad.fnal.gov ERROR Unable to look up wlcg-wpad.cern.ch ERROR Unable to look up wlcg-wpad.fnal.gov ERROR unable to get list of caches ERROR Unable to look up wlcg-wpad.cern.ch ERROR Unable to look up wlcg-wpad.fnal.gov |
| 9 | 2021-11-01 | Unable to look up wlcg-wpad.cern.chUnable to look up wlcg-wpad.fnal.gov |
-
The Chicago XrootD cache has a performance issue related to a scenario with a slow origin on the redirector. If a cache has cache misses that require data retrieval from a slow origin, the data retrievals queue up. There appears to be a queue limit that is cche specific rather than origin-specific. As a result, all cache misses for all origins from that cache are affected by a single slow origin that leads data retrievals to queue up. The response to the cache misses thus slows down. This scenario implies that a single slow origin can, in principle, lead to all caches slowing down. Thus lack of response to cache misses globally across the entire data federation. We consider this a fundamental flaw of the system as one bad apple can affect everybody that uses the data federation.
- The Kansas city XrootD cache has an overload issue due to any issue with GeoIP localization. GeoIP defaults to the geographic middle of the USA when it can not resolve the geographic location of the IP of the client. Kansas City is the closest cache we have to the middle of the country. Therefore, if any client IP can not be resolved, it always defaults to the Kansas city cache. In our test, this has happened often enough to overload the Kansas City Cache, making it unusable.
- The system to check the closest cache needs a review. For example, several sites are using only the Kansas City Cache. See suggestions below.
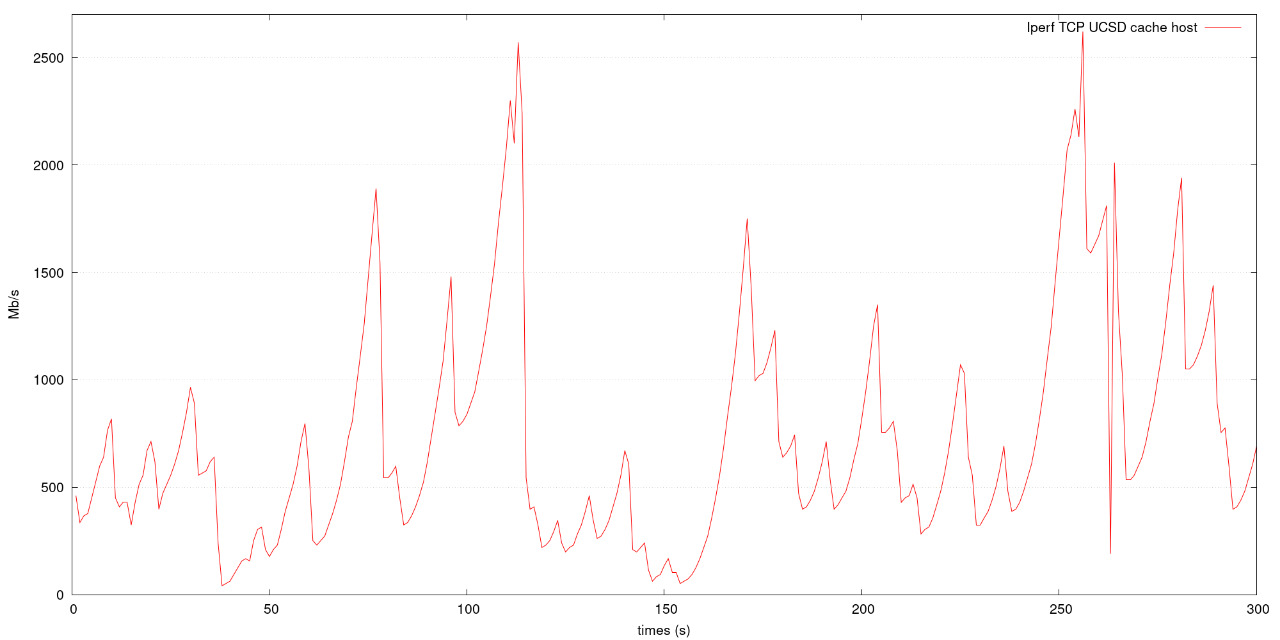
- UCSD XrootD cache is slow compared with the other caches. For example, the UCSD cache is 70% slower than other cache servers. This issue is not understood at present. Figure 3 shows the data transfer ratio from each cache requesting data from the Chicago node, Figure 4 shows the Iperf test between UCSD cache host and Chicago OSG login node, and Table 3 shows the latency from each cache to the Chicago node.
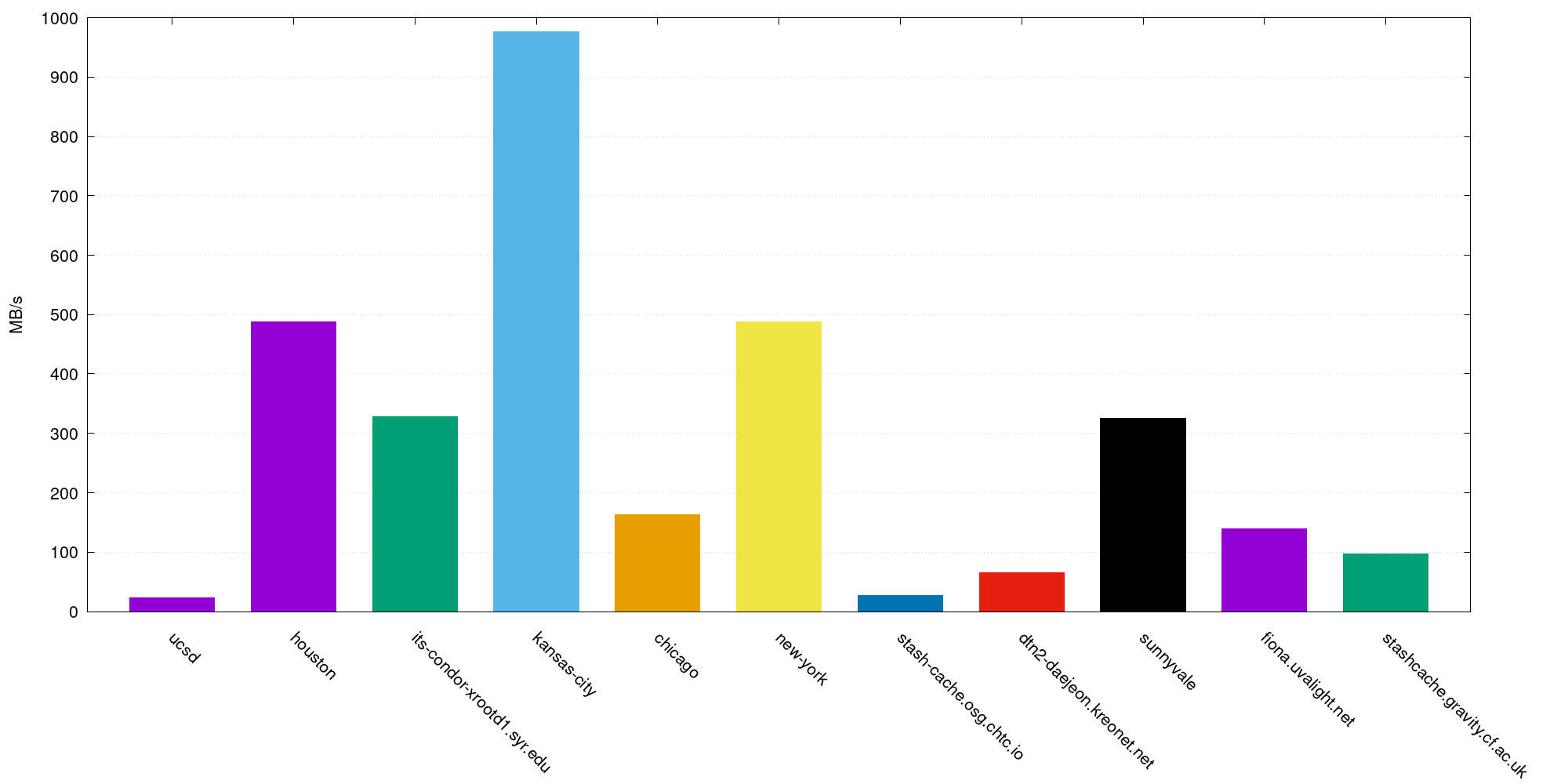
Table 3: Average latency between Chicago and the host.
| Cache | Latency | Linear distance - cities |
|---|---|---|
| ucsd | 58.8ms | 1731.81 miles |
| houston | 24.6ms | 941.90 miles |
| its-condor-xrootd1.syr.edu | 13.7ms | 590.11 miles |
| chicago | 0.649 ms | 0 miles |
| new-york | 19.6 ms | 710.75 miles |
| dtn2-daejeon.kreonet.net | 159 ms | 6597.25 miles |
| osg-sunnyvale-stashcache.nrp.internet2.edu | 46.4 ms | 1815.37 miles |
| fiona.uvalight.net | 108 ms | 4105.72 miles |
| stashcache.gravity.cf.ac.uk | 113 ms | 3831.08 miles |
-
The +DESIRED_Sites instruction is not working sometimes, which requires some extra steps to check if the job was on the right site. This is not understood at present. We are concerned that this indicates a fundamental bug in the HTCondor matchmaking.
-
OSG login node is very slow sometimes, causing problems in the job submission process.
-
The fastest way to access the data is, in order, CVMFS, stashcp, and xrdcopy. However, to use CVMFS is necessary to wait for the synchronization between the /public and cvmfs dir. Figure 5 shows one test executed to measure the data access on OSG, the error bars show the standard deviation from the time measure from 100 jobs, and each bar shows the time to execute each operation from the Chicago nodes.
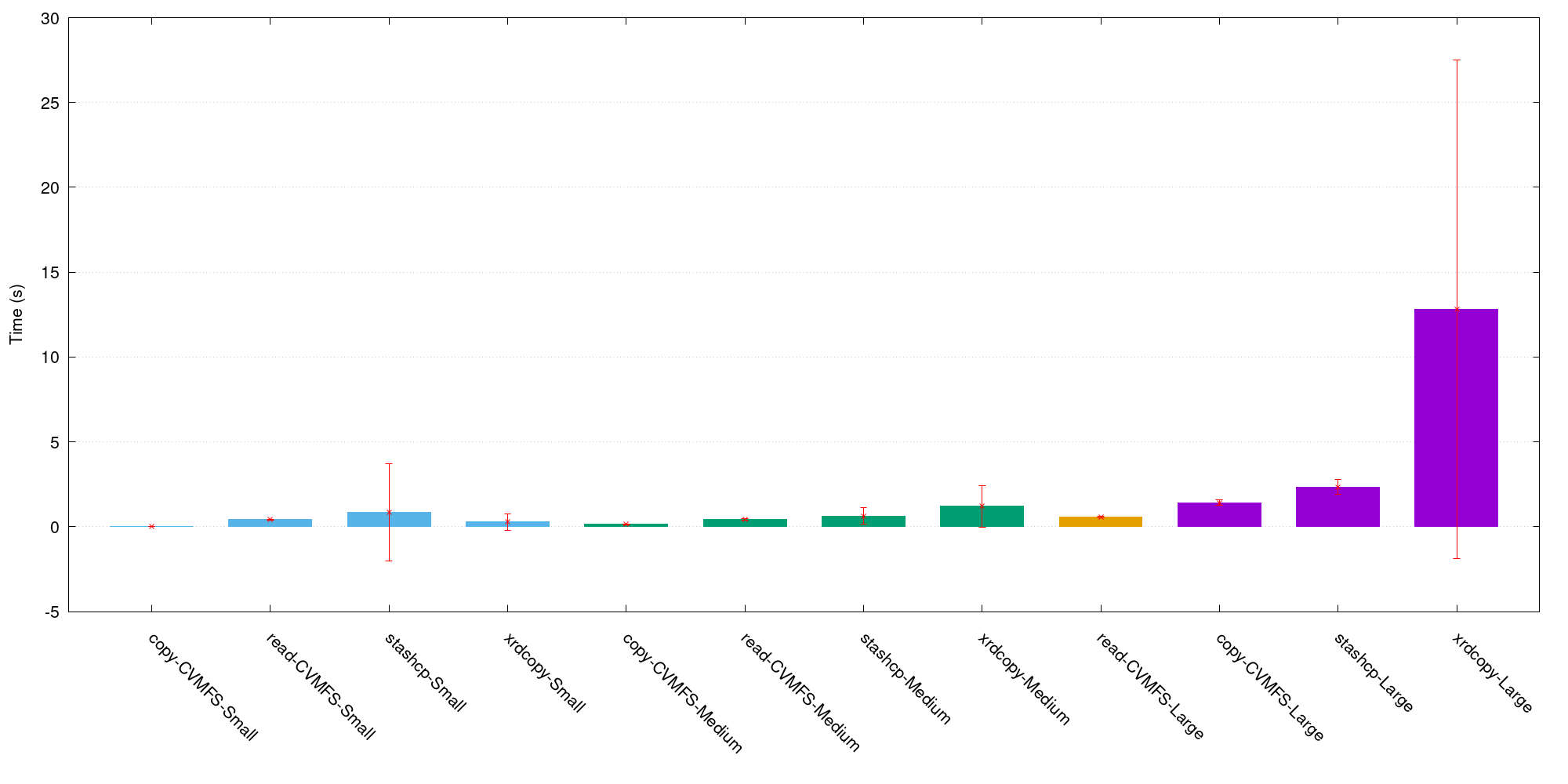
- Looking at the XrootD cache systems (with the nearest location), all the tests performed and the files are on the cache, there is a speed up the data access an average of 5 times.
Recommendations
To prevent or solve the issues, this is a set of recommendations:
-
Develop a monitoring to track the load on the XrootD caches.
-
Create a monitoring system to check the “health” of the cache, origins, and redirectors in such a way that “slow origins” can at least be detected, and maybe even disabled to protect data access to other origins. (More on this in next bullet.)
-
Engage with the XRootD team to solve the fundamental problem with a single origin slowing down the entire data federation. This is a conceptual problem of the system that we need a long-term solution that is carefully designed together with the XRootD development team.
- Alternatively, and maybe more short term, develop a deployment scheme that isolates different origins, protecting them against each other.
- Analyze the Stashcp GeoIP system to detect any failure avoiding the overhead on the Kansas city cache. We propose that anytime GeoIP returns to the middle of the USA, we simply pick a cache at random or some other equivalent remediation.
- Analyze why certain sites seem to always hit the Kansas City cache. Maybe none of their worker node Ips are GeoIP locatable? Maybe some other solution needs to be implemented for those sites?
-
Start a debugging program to understand why HTCondor matchmaking matches some of the time incorrectly. We are concerned that this is a fundamental bug somewhere in HTCondor but have no evidence for it at this time. Therefore, we consider this out of scope for the present study but necessary to follow up.
-
Analyze the UCSD cache to check the reason for the slow data rate;
-
Monitoring the load on the login nodes on OSG.
- Check the version of the Stashcp on the OSG site; There are new improvements on the latest version, and some OSG sites are using an older version.
References
[1] Ieee standard glossary of software engineering terminology. IEEE Std 610.12-1990, pages 1–84,1990.
[2] E.A. Luke. Defining and measuring scalability. In Proceedings of Scalable Parallel Libraries Conference, pages 183–186, 1993.
[3] S. Ali, A.A. Maciejewski, H.J. Siegel, and Jong-Kook Kim. Definition of a robustness metric for resource allocation. In Proceedings International Parallel and Distributed Processing Symposium, pages 10 pp.–, 2003.
[4] S. Ali, A.A. Maciejewski, H.J. Siegel, and Jong-Kook Kim. Measuring the robustness of a resource allocation. IEEE Transactions on Parallel and Distributed Systems, 15(7):630–641, 2004.
[5] Derek Weitzel, Brian Bockelman, Duncan A. Brown, Peter Couvares, Frank W¨urthwein, and Edgar Fajardo Hernandez. Data Access for LIGO on the OSG. arXiv e-prints, page arXiv:1705.06202, May 2017.