Multiple files vs. Tar.gz
by Fabio Andrijauskas, as of January 7, 2022
The objective of these tests is to check if it is faster to transfer each file separately or compress all the files on a tar.gz file for a job on the Open Science Grid (OSG) using the HTCondor. Was used one tar.gz file with 50000 50KB (each file has a random content, the compress ratio is ≈ 1 : 1) to copy to the node, and the MD5 hash was calculated using the code from Listing 1 e 2.
Listing 1: Job requesting the tar.gz file.
error = short$(ProcId).error
Arguments = $(ProcId)
output = short$(ProcId).output
log = short$(ProcId).log
Requirements = GLIDEIN_Site == ”CU − Research Computing”
+DESIRED_Sites = ”CU − Research Computing”
transfer_input_files = /home/fandri/data2.tar.gz
should_transfer_files = yes
request_cpus = 1
request_memory = 100 MB
request_disk = 100 MB
executable = 1.sh
queue 20Listing 2: Script to check the data
#!/bin/bash
tar −xf data.tar.gz
cd data
for f in file *;
do
md5sum $f
doneCode on Listing 3 e 4 was used to process 50000 files 50KB each (files have a random content, the compress ratio is ≈ 1 : 1) to copy to the node and calculate the MD5 hash.
Listing 3: Job
error = short$(ProcId).error
Arguments = $(ProcId)
output = short$(ProcId).output
log = short$(ProcId).log
Requirements = GLIDEIN_Site == ”CU − Research Computing”
+DESIRED_Sites = ”CU − Research Computing”
transfer_input_files = /home/fandri/data2/
should_transfer_files = yes
request_cpus = 1
request_memory = 100 MB
request_disk = 100 MB
executable = 1.sh
queue 20Listing 4: Script
for f in file *;
do
md5sum $f
doneTable 1 shows the results using 50000 50KB (each file has a random content) on a tar.gz and multiple files requesting from Chicago - IL to:
- SU-ITS (Syracuse University - New York - NY);
- SDSC (San Diego - CA);
- CU – Research Computing (Colorado University - Boulder - CO).
The tests were executed 20 times. Table 1 contains statistical data from all the tests:
- “AVG transfer” column shows the average time to transfer the files;
- “AVG decompress” show the average time to decompress the files;
- “AVG proc” indicates the average time to process the files
- “AVG total proc” show the sum of the average time for all process steps (transfer, decompress, and process);
- “STDEV transfer” represents the standard deviation for the transfer time;
- “STDEV untar” represents the standard deviation for the decompress time;
- “STDEV proc” means the standard deviation for the processing time.
Table 1: Results from tests on SU-ITS, SDSC, and CU site from the Chicago OSG login.
Site | AVG transfer | AVG decompress | AVG proc | AVG total proc | STDEV transfer | STDEV untar | STDEV proc |
|---|---|---|---|---|---|---|---|
SU-ITS - targz | 211.59s | 35.24s | 868.80s | 1115.62s | 84.57s | 7.39s | 437.79s |
SU-ITS - files | 202.94s | – | 973.18s | 1176.12s | 40.41s | – | 296.78s |
CU - targz | 77.84s | 17.32s | 179.22s | 274.38s | 19.22s | 1.36s | 54.69s |
CU - files | 85.45s | – | 178.52s | 263.96s | 23.28s | – | 57.17s |
SDSC - targz | 40.309s | 27.99ss | 353.99s | 422.22s | 22.99s | 6.5s | 56.86s |
SDSC - files | 37.82s | – | 559.73s | 597.53s | 19.13s | – | 196.70s |
Figure 1 shows the time to transfer the data using multiple files or using only one tar.gz file. The error bars are the standard deviation. Due to the standard deviation of all measures, there is no statistical difference between the test using tar.gz or the multiple files.
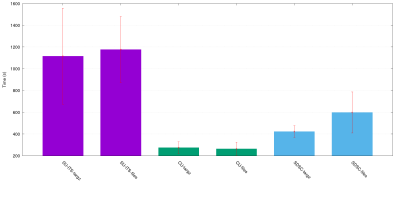
All tests show no statistical difference when using the tar.gz or the multiple files. The investigations of the HTCondor source code (https://github.com/htcondor/htcondor/blob/master/src/condor_utils/file_transfer.cpp) and HTCondor developers comments, it is possible to conclude that there is no hugely overhead for the multiple file approach on HTCondor. The only vantage to use the tar.gz is the possibility to compress the data and have less network usage.